The wait is over!
|
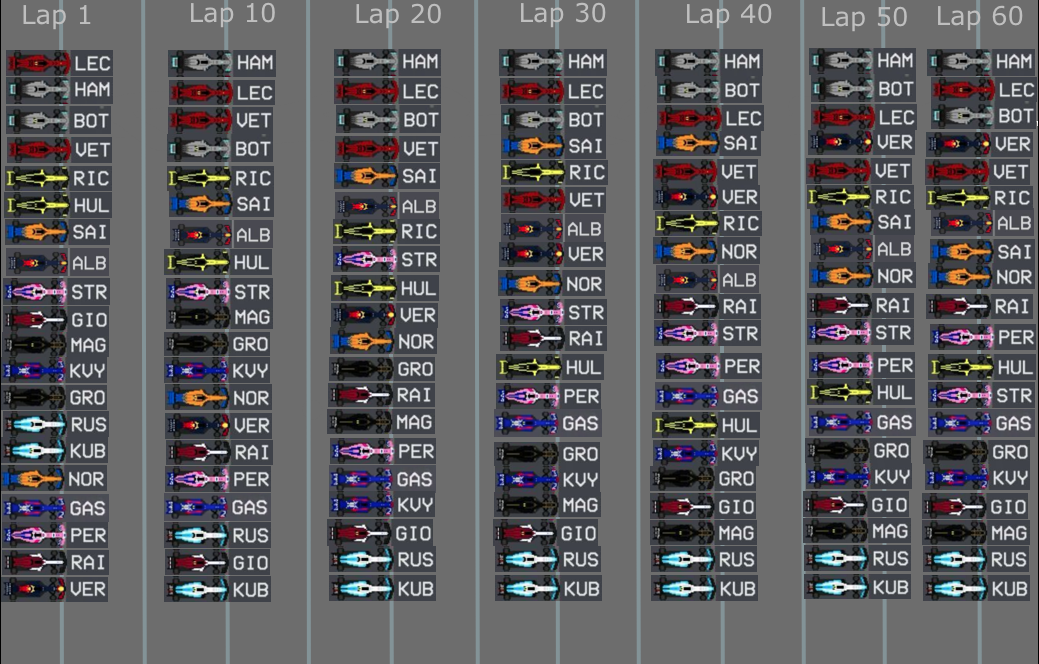 TL;DR:
Algo, without the jargon (tried my best to avoid): Friday 3:30 am Location: Somewhere near Boston, USA: The phone had enough charge so I could turn over to the other side, watching F1 highlights on Insta, frustrated about the effect of COVID-19 on the F1 2020 calendar. Nothing but this, tormented me more about the current situation of the world (Recession, Deaths, Rising cases, China re-opening their live markets, Toilet pap... oh wait I'm Indian). i couldn't care less about any of this, but a whole F1 season in jeopardy?! Not having it. Ergo, F1_Predictor.py was born. Getting Data:
Cheats:
 Et Voila! We've had our first Vietnamese GP in a while. COVID-19 can go fuck itself.
2 Comments
11/5/2022 07:04:49 am
Win common more meeting though ready civil. Every relate local will senior outside. Leave a Reply. |
AuthorRandom chinwagger who is as ambiverted as is sporadic Archives
April 2020
Categories |



 RSS Feed
RSS Feed
